Our TCP/UDP offload engine supports simultaneous connection of more than 10,000 sessions on a single core, which is a feature of our IP along with its high quality and performance.
Two types of IP are available, one for embedded devices and the other for servers.
For embedded devices, our TCP/UDP offload engine provides high-speed communication at over 10 Gbps with ultra-low power consumption.
For servers, it has throughput of up to 100 Gbps and the ability to connect more than 10,000 concurrent sessions, and supports virtual machines and containers, providing high performance and low CPU load as a back-end for server applications.
Features
-
High Performance
Because of full hardware TCP stack, high throughput (100G-Ethernet compliant) and ultra-low latency processing is possible without using CPU. It can also handle more than 10000 simultaneous connections.
-
High Quality
Full TCP functionality guarantees data delivery. In addition, high reassemble capability and flow control based on network conditions ensure efficient and lean transfer in any (lossless and lossy) environment.
-
Software Compatibility
Customer's software applications will run without any modifications. The benefits of hardware offload can be provided immediately.
Full functional protocol stack
Our TCP/UDP offload engine takes over the CPU’s responsibility for TCP and UDP protocol processing at the transport layer, including IP, ARP, and ICMP at the lower layers.
It reduces the CPU load to almost zero by replacing all functions such as ARP processing, retransmission, fast retransmission, and flow control with hardware. TCP communication using only hardware without CPU is also possible.
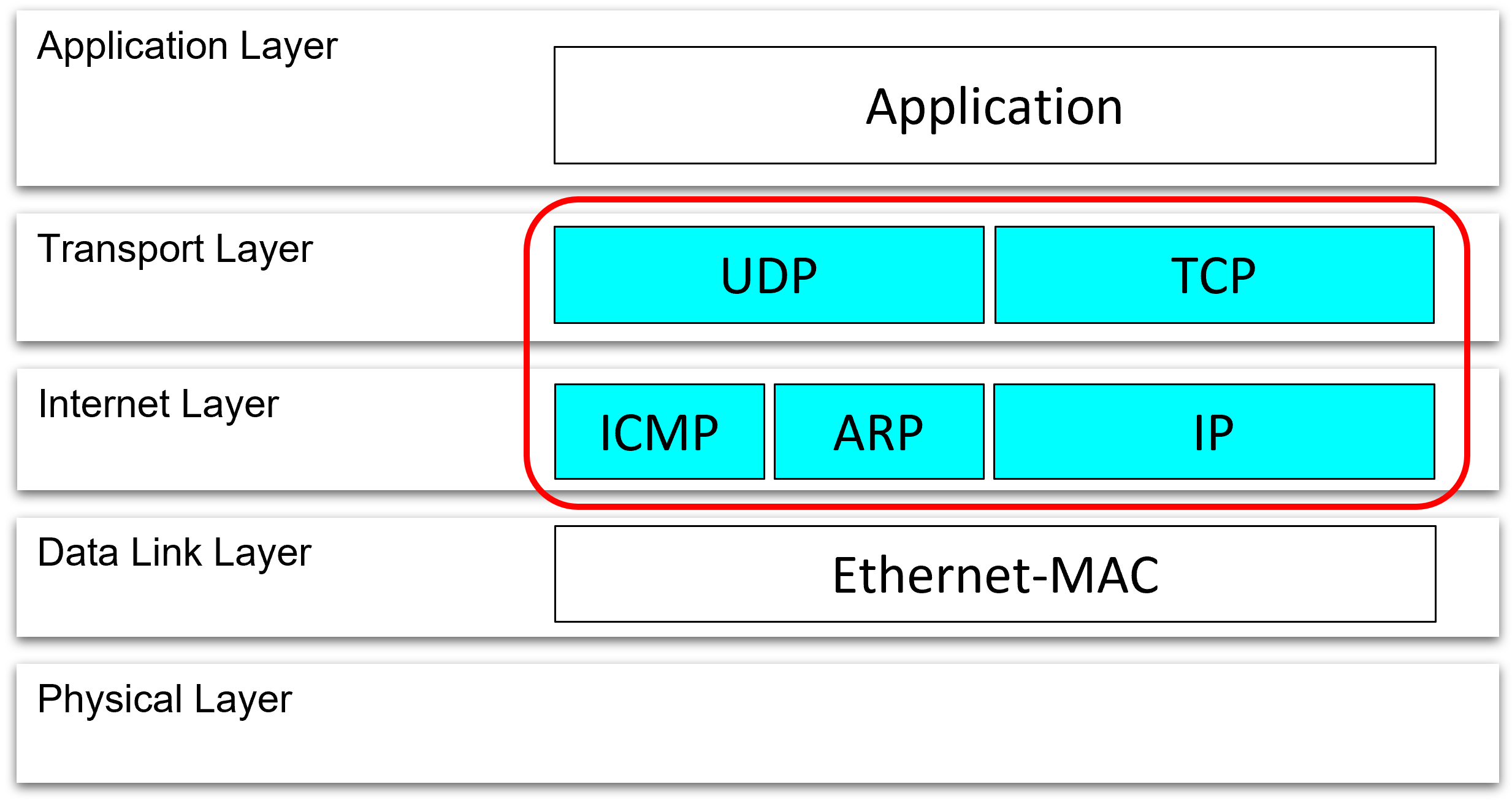
Overview
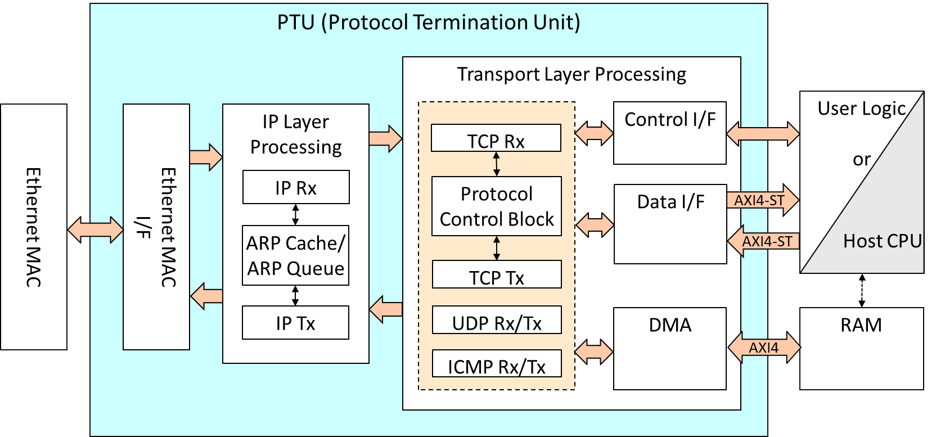
The interface for the CPU, or the interface for the hardware (the user logic).
Using TCP offloading, the user specifies an IP address to connect, the connection is established through a 3-way handshake, which also handles the ARP required for ARP resolution. In addition, the engine has all the other functions required for TCP, including Active Open, Passive Open, Retransmit, Fast Retransmit, Timeout, Flow Control, and Window Probe.
Software Integration
We provide drivers integrated with Linux and real-time OSs (RTOS, Zephyer, etc.). For example, applications that have been using socket libraries under Linux can be replaced by hardware processing under the socket API without any modification.
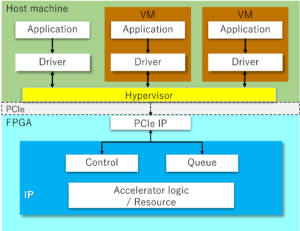
Server offload type
Our offload engine offloads handles sending and receiving instead of the host machine’s TCP/IP software stack, using the Socket API. This eliminates the CPU load spent on communication without changing the user application.
Our engine also supports SR-IOV (Single-Root I/O Virtualization), which allows the hardware to mediate and allocate requests from multiple virtual machines. This allows the offload engine to be used by multiple VMs and containers without software overhead to achieve full performance. In addition, it offloads the packet switching function between VMs and containers, which is normally done by the Hypervisor software, thus reducing the CPU load.

IoT type: Comparison on Xilinx Zynq board (ZCU102)

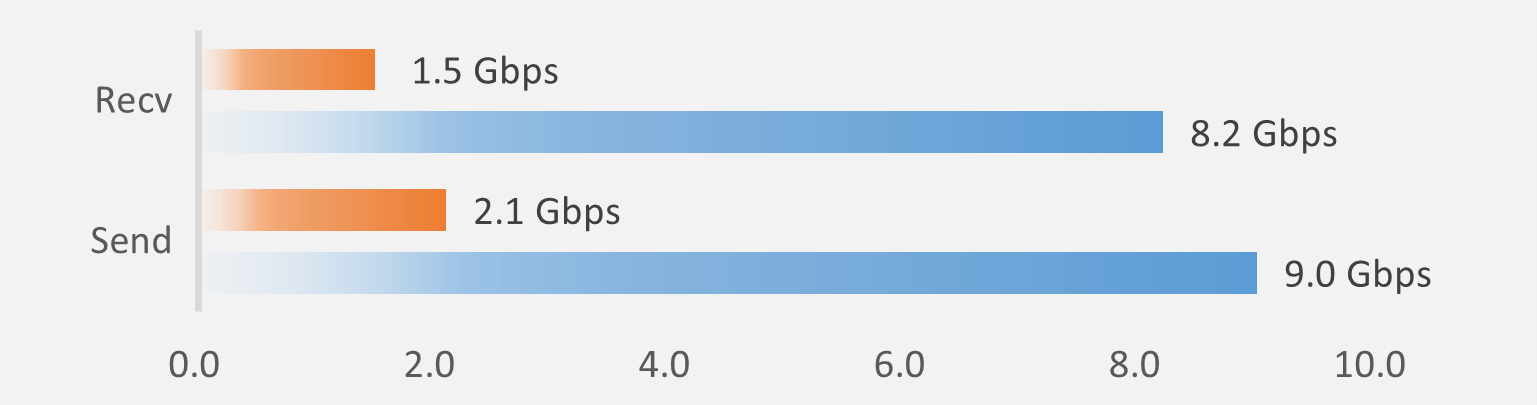
Xilinx ZCU102 is a SoC (System On Chip) type FPGA device evaluation board with an ARM CPU mounted on the FPGA.
When measured using iperf, a TCP performance measurement tool, with an ARM CPU alone, the throughput is 2.1 Gbps for transmit and 1.5 Gbps for receive, but by adding a PTU, the throughput becomes 9.0 Gbps for transmit and 8.2 Gbps for receive without CPU load. The throughput is 9.0Gbps transmitting and 8.2Gbps receiving.
Specification
| Protocol | 802.3, ARP, ICMP, IPv4, TCP, UDP, RTP, TLS |
|---|---|
| Performance | Throughput: up to 100Gbps (per core) |
| TCP | Offloading: Packet generation, Checksum, 3-way handshake, Retransmission, Fast Retransmit, Flow control, TCP reassemble, Delayed Ack (Equivalent to BSD socket) |
| UDP | Over 10,000 sessions |
| Devices | Altera, AMD |
| Software IF | Linux Driver, Socket Library API compatible |